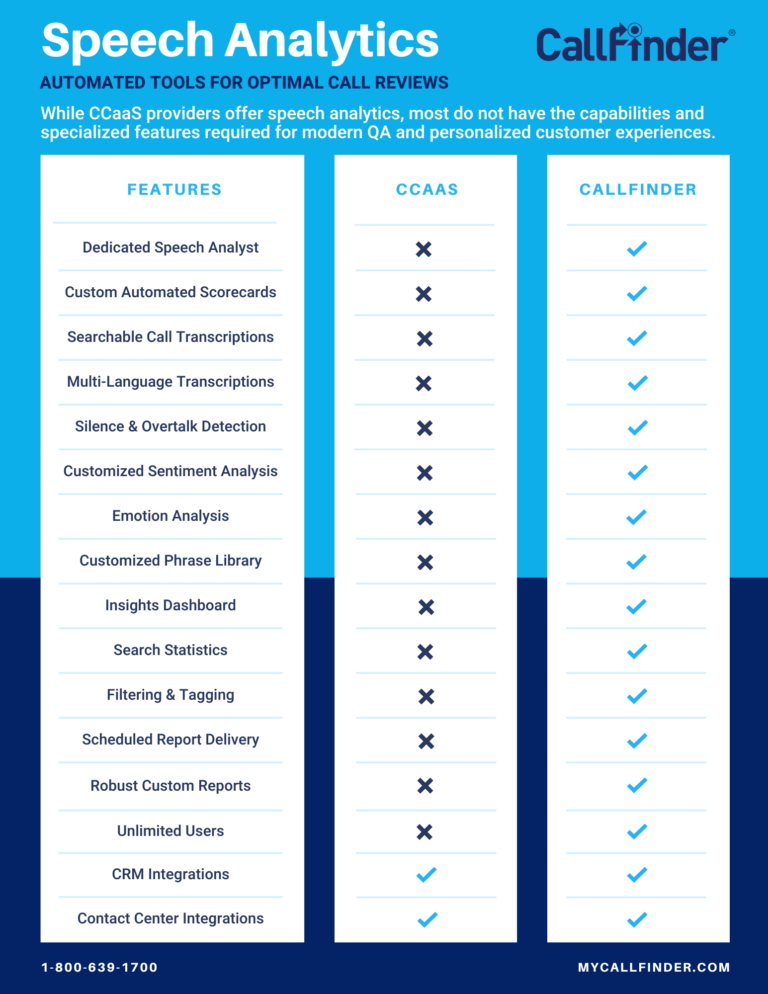
There are two types of technology that drive a speech analytics platform. One is Large Vocabulary Continuous Speech Recognition, or LVCSR. This is essentially speech-to-text technology and is dependent on the dictionary to identify words that are contained and spoken within phone conversations.
The second type of technology is phonetics-based. This technology uses original audio files to identify the string of phonemes, which are the smallest units of sound that make up a language, to match the search criteria put forth by the user.
How Does a Phonetics-based Engine Differ?
Phonetics-based speech analytics technology is not dependent on the words within a dictionary and can identify slang, unique product names and different regional dialects.
For example, here are some situations of the spoken word, which may vary from region to region. A phonetics-based solution can pick up all of the calls that reflect the following types of phrases:
1. Appointment setting:
- “I’d like ta make an appointment.”
- “Have you ever ben here before?”
2. Thanking the caller:
- “Heng you for calling”
- “Thank you fer calling”
- “Then kyou fur callin”
3. Information collection by agents:
- “Whaddiz your first name?”
- “Whuddiz your first name?”
- Other benefits of phonetics-based engines
- It can be faster than speech-to-text.
- It allows for broad search terms to be analyzed, like industry jargon, unique product names, acronyms, accents and dialects
- For more on how to use a speech analytics solution to help your business identify specific phrases and keywords being spoken by your customers or employees, contact us any time.